Keen (or keen.io) is an embedded analytics tool from the company of the same name headquartered in San Antonio, that is built an Apache Kafka and focuses on event data. Keen’s presentation library can be used to embed and deliver metrics within a UI.
N/A
Looker
Score 8.2 out of 10
N/A
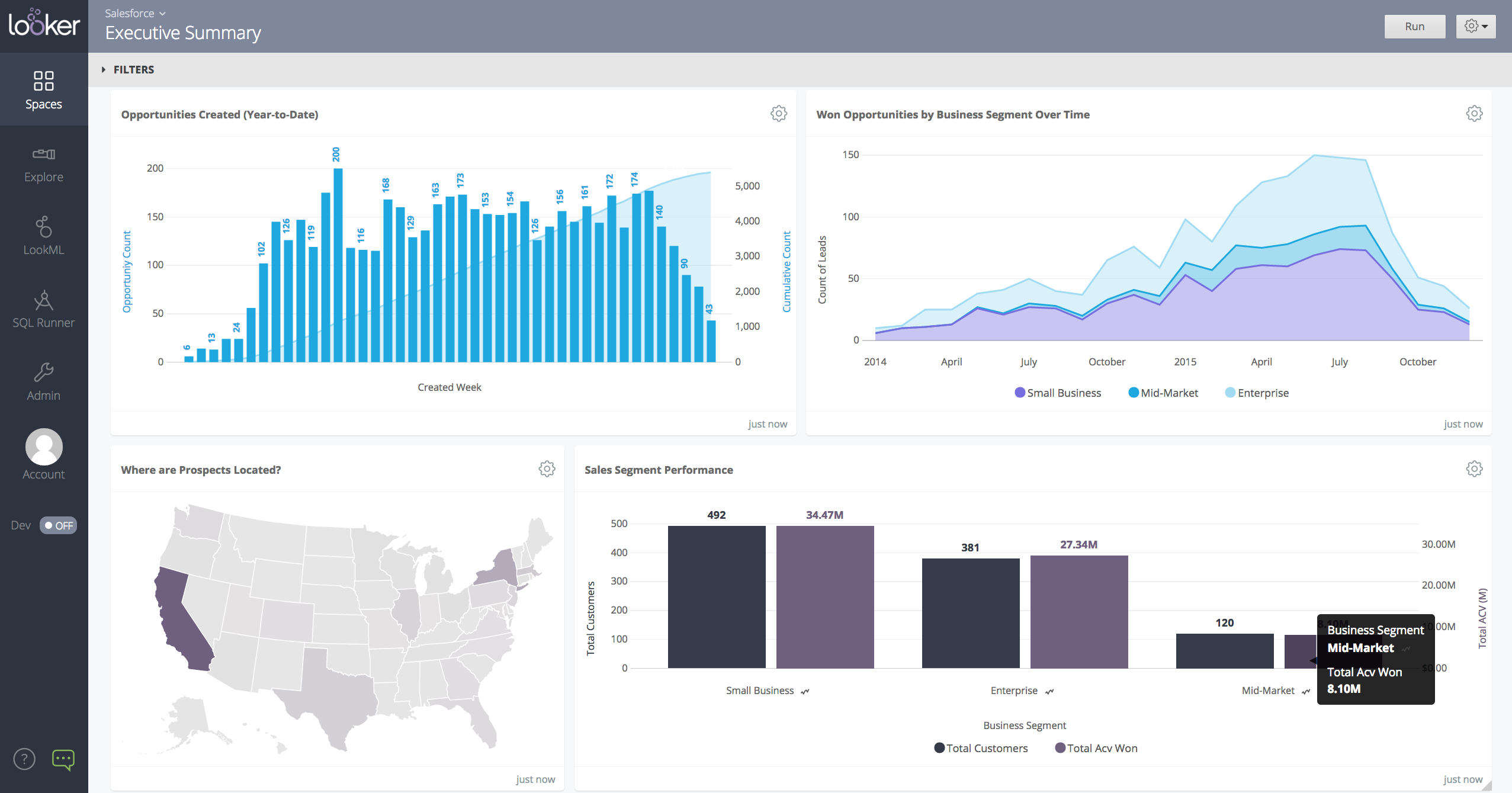
Looker is a BI application with an analytics-oriented application server that sits on top of relational data stores. It includes an end-user interface for exploring data, a reusable development paradigm for data discovery, and an API for supporting data in other systems.
Overall I think Keen IO is generally easier to use and more friendly towards new or novice users than other platforms. If you are just looking for a quick and easy solution, Keen IO might be the way to go. The cost of obtaining the software is a con when compared to some other …
Quick dashboards from Google Sheets - Easier to do the graphs than in Google Sheets - Operational dashboards to be used in the day-to-day work - It is good both for retrospective data and to do a pulse check of the current status - Better for not giant amounts of data and not multiple data sources. - If you need a lot of graphs to be displayed on the same page, it can be a bit glitchy during configuration (then the use works fine).
Filtering - you can filter across different dimensions and metrics to get a more specific "cut" of data
Refreshing - data automatically ingests into Looker which allows reports to be updated and backfilled in real time
Conditional Reporting - you can leverage Looker's reporting features to flag when a given metric or KPI falls below or above a specified threshold. For example, if you had a daily sales benchmark in a SAAS organization, you could use Looker to flag whenever daily sales falls above or below the benchmark
Looker is less graphical or pictorial which makes it less attractive
Consumes a lot of memory when there are multiple rows and columns, impacts performance too
At times when we download huge chunks of raw data from Looker dashbords, the time taken to prepare the file is enormous - The user fails to understand if Looker has frozen or if the data is getting prepared in the background for downloading. In turn, user ends up triggering multiple downloads
We've been very happy with Looker so far, and all teams in the organization are starting to see its value, and use it on a frequent basis. It has quickly become our accessible "source of truth" for all data/metrics.
Looker is relatively easy to use, even as it is set up. The customers for the front-end only have issues with the initial setup for looker ml creations. Other "looks" are relatively easy to set up, depending on the ETL and the data which is coming into Looker on a regular basis.
Never had to work with support for issues. Any questions we had, they would respond promptly and clearly. The one-time setup was easy, by reading documentation. If the feature is not supported, they will add a feature request. In this case, LDAP support was requested over OKTA. They are looking into it.
They have minor similarities, so they are not easily comparable. Keen is one of a kind and does not have a great alternative. It just needs a little work and developers will be addicted to it.
Looker is an off-the-shelf, free tool for Google business users. Other than the internal cost of time to build, we had no costs to set up what we needed to do. Knowledge sharing internally and using templates greatly reduced this cost, making the overall cost very low.
Allowing others to self-serve their own analytics and connect it to Looker simply and easily has helped unblock the central data team so they can instead focus on validated dashboards whilst stakeholders manage their day-to-day analysis themselves. Countless engineering hours have been freed up by not having to manage every user permission for each BI tool; we have a BYOBI approach; Bring Your Own BI
Creation and management of a semantic layer (LookML =Looker Modeling Language ) allows peoples sandboxes and production databases to become clutter free. Minor adjustments, conditional fields, and even some modelling can all be done in LookML which doesn't need oversight or governance from the central data team.
LookML, specifying drilldown fields and their sub-queries, as well as generally creating dynamic parameters with Liquid are all great features, but can have a steep learning curve. it may take some time to understand how to create this middle layer correctly, or even pose a risk of inheriting complex code from another source which can be unmaintainable if it becomes too big. Some level of governance is recommended if Looker is used by a large number of editors.